


摘要:轻量级神经网络降噪方法,解析 ZegoAIDenoise 的算法实现!
轻量级神经网络降噪——ZegoAIDenoise
当下,用户在进行音频通话时常常置身于各种不同的场景中,嘈杂的背景声音以及非稳态噪音往往会对通话产生干扰,其中非稳态噪音是指在时间分布上不连续,并有其形态特征的噪声,是相对稳态噪声而言的,例如,鼠标点击声、键盘声、敲击声、空调声、厨房碗碟碰撞声等都属于非稳态噪音。
而基于信号处理的传统音频降噪算法对于平稳噪声有比较好的降噪效果,但是对于非平稳噪声,低信噪比等复杂场景,降噪效果较差,甚至失效。
随着目前深度学习的广泛应用,基于神经网络的音频降噪算法大量涌现,这些算法无论在降噪效果上,还是泛化能力上,都能取得比较好的结果,很好的弥补了传统算法的不足。
但是,这些方案大多是直接基于短时傅里叶变换后的频域信号或者时域信号的端到端方案,存在网络模型过于复杂,性能消耗巨大等问题,给实时场景交付提出了很大的挑战。
基于上述挑战,ZEGO 即构科技提出了一个轻量级的神经网络降噪方法 —— ZegoAIDenoise,对于平稳和非平稳噪声都有很好的降噪效果,保证了语音的质量和可懂度,同时将性能开销控制在一个很低的量级,与传统降噪算法相当,成功覆盖大部分中低端机型。
那么今天将详细为大家介绍 ZegoAIDenoise 的实现原理,及如何在低性能开销的前提下,提高深度学习算法的降噪效果及泛化能力。
ZegoAIDenoise 算法原理解析
ZegoAIDenoise 采用传统算法和深度学习相结合的 Hybrid 方法,为了降低性能开销,采用频域分成子带方案,并无限缩小深度学习网络模型,用尽量小的网络模型达到更好的降噪效果。
1、信号模型
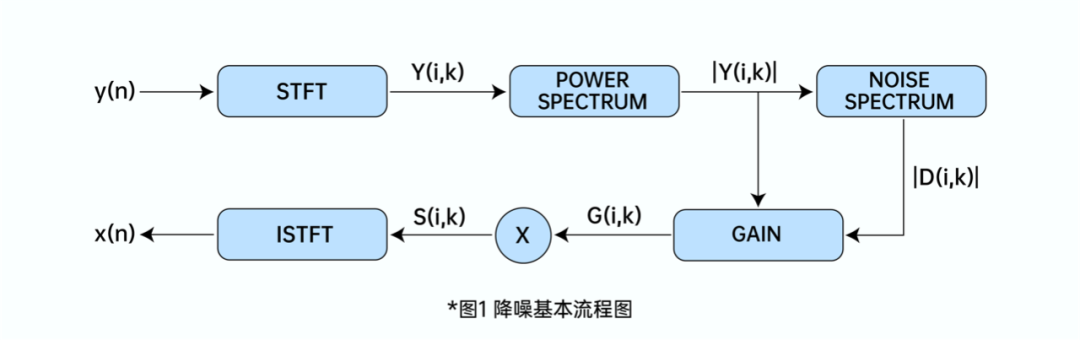
如图 1 所示,传统降噪基本原理多采用谱减法,即根据谱能量估算噪声能量及各频点增益,得到干净语音。所以,只要 ZegoAIDenoise 能准确估算出频点增益 G,就能从带噪的麦克风信号中得到期望的干净语音信号 x(n)。
频点增益 G 的推导过程如下:
y(n) = x(n) + d(n) ……… (1)
公式(1) 中,x(n)代表干净语音信号,d(n)代表噪声信号,y(n)代表麦克风采集的信号。
对公式 (1) 做 STFT 之后,得到公式 (2):
Y(i, k) = X(i, k) + D(i, k) ……… (2)
其中,Y(i, k),X(i, k) 和 D (i, k) 分别代表 y(n),x(n),d(n)的频域信号,i代表第i个时域帧,k代表频点,由此,得到公式(3):
G(i, k) = |S(i, k)| / |Y(i, k)| ……… (3)
G(i, k) 代表的是估算的频点增益。所以,只要估算出 G(i, k),就能通过带噪信号Y(i, k),估算出语音信号 S(i, k)。
2、特征值
为了避免大量的输出,避免使用大量神经元,ZegoAIDenoise 决定不直接使用语音样本或者能量谱。作为代替,ZegoAIDenoise 考虑一种符合人类听觉感知的频率尺度 —— 巴克频带尺度,总共用了 22 个子带。
为了更好估算 G(i, k),需要选择更能代表语音特性的特征,从而区分语音和噪声,ZegoAIDenoise 引入了基于基因周期的梳状滤波器 (4)。式中,M 是中心抽头两侧的周期数,通过调整 M 值,改变时延。
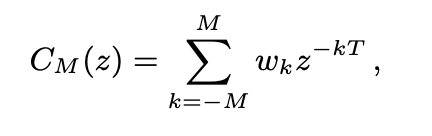
自适应目标增益,如果通过梳状滤波器得到的相干性能量低于干净语音的相干性能量,则调整目标增益,限制最大衰减量,能有效地解决在大嘈杂的场景的过抑制问题。
使用梳状滤波器,能有效地提高语音的谐波特性,降低谐波间噪声,用一定时延的代价,换取更好的降噪效果。
3、CRNN网络模型
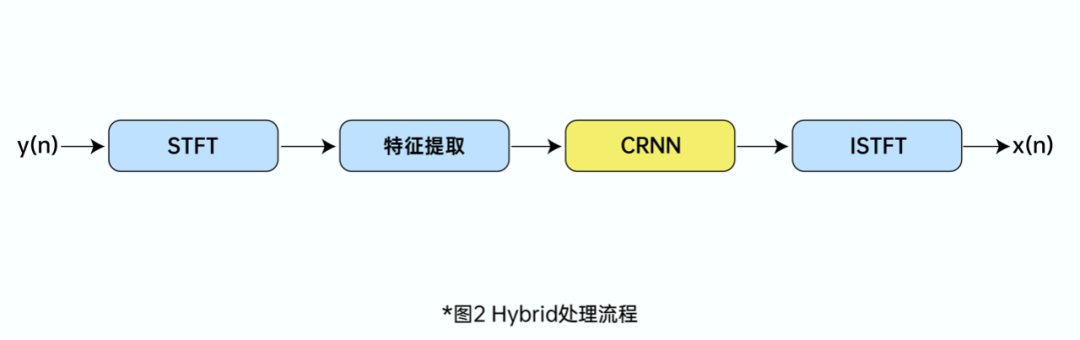
如图 2 所示,ZegoAIDenoise 采用传统算法和深度学习相结合的 Hybrid 方法,传统算法对实时数据进行特征提取及后处理,深度学习估计子带增益,Hybrid 不仅能满足实时性要求,同时能适应场景复杂的噪声环境,给实时通信带来良好的用户体验。
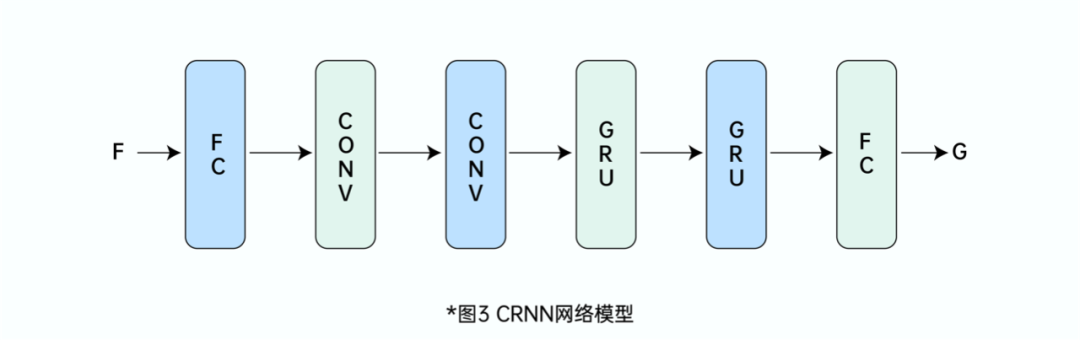
如图 3 所示,CRNN 模型使用两个卷积层和多个 GRU 层。卷积层的使用能进一步地提高特征提取的有效性及泛化能力。
训练时,通过对语音和噪声应用不同的随机二阶零极点滤波器,ZegoAIDenoise 改进了模型的泛化性。ZegoAIDenoise 还对两个信号应用相同的随机频谱倾斜,以便更好地概括不同的麦克风频率响应。为了实现带宽独立性,ZegoAIDenoise 采用了一个低通滤波器,其随机截止频率在 3 kHz 和 16 kHz 之间。这使得在窄带到全波段音频上使用同一型号成为可能。
训练过程中,损失函数的设计也尤为重要。除了平方误差,ZegoAIDenoise 还引入四次方误差来强调训练估计错误的代价。同时,还增加了注意力机制,用以减少对语音的损伤。
ZegoAIDenoise 效果及性能对比
在对比项上,ZegoAIDenoise 主要和传统降噪及 RNNoise 降噪进行了对比,无论在 MOS,还是在可懂度上都有明显提升。
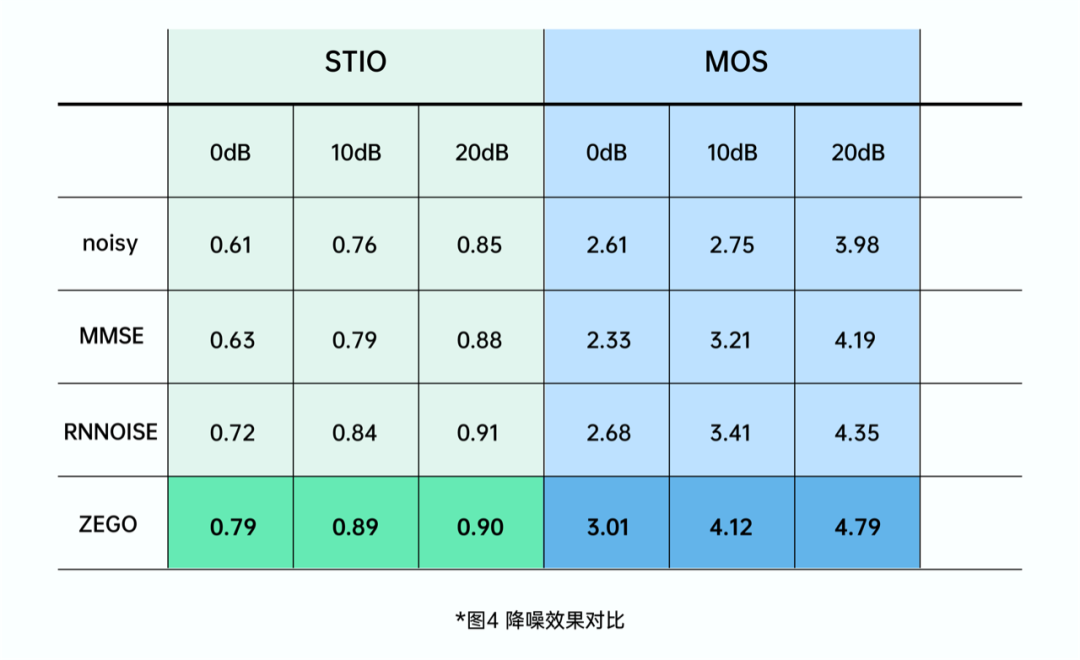
如上效果展示,ZegoAIDenoise 针对不同的噪声类型及场景,均取得比较理想的降噪效果。在实时处理的性能测试方面,默认采样率 32kHz,帧长 10ms,在 1.4G Hz主频的 iPhone 6上,CPU 性能开销为 1% 左右,与 WebRTC 的通用降噪相当。所以,ZegoAIDenoise 无论在降噪效果、泛化能力,还是性能开销上,都取得了长足的进步,实现了机型和场景的全覆盖。
综上所述,ZegoAIDenoise 实现了一个轻量级的神经网络降噪方法,无论是在稳态还是非稳态的噪声环境,都能取得比较好的降噪效果,高质量的音频降噪能够有效提升用户实时互动体验。
目前,ZEGO Express SDK 已正式提供 AI 降噪功能,开发者可以在使用麦克风采集声音时,对声音进行降噪处理,并在传统降噪(详情请参考 噪声抑制)消除稳态噪声的基础上,同步处理非稳态噪声(包括鼠标点击声、键盘声、敲击声、空调声、厨房碗碟碰撞声、餐厅嘈杂声、环境风声、咳嗽声、吹气声等非人声噪声),保留纯净语音,提升用户的通话体验。
未来,我们会结合具体行业和场景,引入更多的深度学习算法,提升产品的场景适应能力,给用户提供更好的音频体验!
(详细实现文档可点击链接:https://doc-zh.zego.im/article/14527)



