


在 WebRTC 中,如果有一件事能为你带来更好的媒体质量,那就是减少(或消除)数据包丢失。没有其他任何东西能像它一样有效。
我想在这里解释一下丢包、丢包不可避免的原因,以及面对丢包,我们有哪些方法可以提高 WebRTC 媒体的恢复能力和质量。
作者:Tsahi Levent-Levi
译自:https://bloggeek.me/fixing-packet-loss-webrtc/
编译:小极狗
为什么 WebRTC 会出现丢包?
现代网络和 WebRTC 出现丢包的原因有很多。现列举其中几个:
- 由于设备与接入点之间的距离以及其他障碍物(物理干扰或空中干扰),无线和蜂窝网络可能会受到影响
- 路由器和交换机可能会拥塞,导致延迟和丢包
- 以太网电缆有时会出现故障
- 交换机之间的连接并不总是那么干净
- 媒体服务器工作不正常或流量过大
- 熵。我们越是小型化和压缩事物,熵就会越大(我加了这一条,只是为了听起来更方便)。
- 设备有时可能表现不佳
我们认为互联网是一个可靠的网络。你用浏览器打开一个网页,一般网页就会加载出来。如果加载不了,那就是网络或服务器有问题。故事结束。这是因为数据包丢失是通过重新传输丢失的数据包来处理的。代价是什么?你需要等待更长的时间来加载页面。
对于 WebRTC,我们处理的是实时通信。因此,如果有东西丢失,几乎没有多少时间来修复。
丢包是 WebRTC 应用程序非常头疼的问题!
如何克服丢包呢?
说到 WebRTC 和 VoIP,丢包是不可避免的。你无法真正避免它们。那么问题来了,我们能做些什么呢?
这里有四种不同的方法,可以结合使用以获得更好的用户体验:
- 减少数据包丢失:如果数据包丢失减少,用户体验就会提高
- 隐藏数据包丢失 (PLC): 一旦出现数据包丢失,我们需要想办法向用户掩盖这一事实
- 重传丢失的数据包 (RTX):假设有足够的时间,我们可以尝试重传丢失的数据包
- 提前纠正数据包丢失(FEC):当我们知道数据包丢失的可能性很高时,我们可能希望多发送几次数据包,或添加一些纠错机制来处理潜在的数据包丢失。
接下来,让我们逐一回顾这四种方法。
减少数据包丢失
这是最重要的解决方案。
如果丢包少了,那么在试图 “修复 “这种情况时就不会那么头疼了。因此,减少丢包应是首要目标。由于无法完全消除丢包,我们仍需要使用其他技术。但首先要减少丢包量。
WebRTC 中基础设施元素的位置
媒体服务器和 TURN 服务器的放置位置,以及 WebRTC 服务的流量路由方式,都会对数据包丢失产生巨大影响。
目前的最佳做法是让 WebRTC 媒体访问的第一台服务器尽可能靠近用户。这背后的原因是,这样可以减少媒体数据包在开放互联网上需要穿越的跳数和网络基础设施组件。一旦进入你的服务器,你对数据如何在服务器之间处理和转发就有了更多的控制权。
在美国的一个数据中心就能满足所有流量的需求。假设你的用户来自该地区,一旦用户开始从大洋彼岸加入,比如……法国,或者印度。你将会看到更高的延迟和更高的丢包率。
这里有几件事:
- 将服务器放置在何处在很大程度上取决于用户及其行为。
- TURN 服务器对于在全球分布很重要,但最终还是要检查有多少实际流量是通过 TURN 服务器进行的
- 如果所有会议都需要媒体服务器,我会尝试在全球范围内布置服务器。我还会把重点放在级联/分布式架构上,让用户加入最近的媒体服务器(而不是为同一会议的所有用户分配特定的服务器)
从哪里开始?
- 了解用户的延迟 (RTT),监控它,努力改进。
- 检查是否存在跨区域路由的地区和用户,根据这些数据加强相关地区的基础设施。
- 既然我们要减少丢包,那就应该监控它
更好的带宽估算
我本该称其为 “更好的带宽管理",但出于搜索引擎优化的考虑,还是将其保留为 “带宽估算"😉。
事情是这样的:
发送量超过网络处理能力、发送方发送能力或接收方接收能力会导致丢包和掉包。
解决这个问题的关键在于带宽管理——你不想发送太少,因为媒体质量会低于你所能达到的水平。你也不想发送太多,因为……嗯……丢包。
你的服务需要能够估算带宽。这需要在每个用户的上行链路和下行链路上进行。
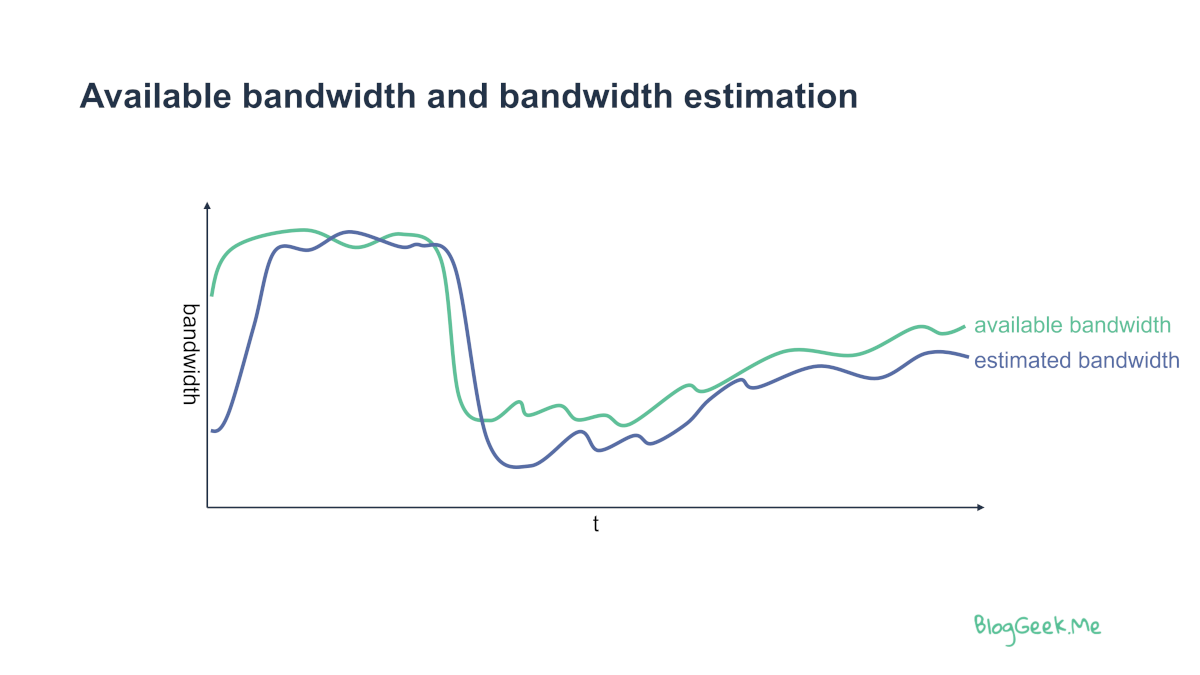
我们面临的挑战是,可用带宽是动态的。在每个时间点,我们都需要对其进行估算。如果估计过高,数据包就会延迟或丢失。如果估计不足,媒体质量就会降低到我们所能达到的水平以下。
WebRTC 的 Web 浏览器实现有自己的带宽管理算法,而且相当不错。媒体服务器有不同的实现方式,其质量也参差不齐。
对于媒体服务器,我们还需要记住,我们不仅要处理带宽估算问题,还要处理带宽管理问题。一旦我们大致知道可用带宽,我们就需要决定在连接上发送哪些数据流以及以何种比特率发送;在做这些决定时,我们要看到会话的全貌(因此是带宽管理而不是估算)。
隐藏数据包丢失 (PLC)
丢包隐藏是我们在事后所做的事情。丢包了,但我们需要为用户做点什么。我们应该如何掩盖丢包问题?
这似乎是最后要处理的问题,但却是我们首先要解决的问题。原因有二:
无论使用何种技术和弹性机制,最终都会出现一定程度的丢包。
我们拥有的其他技术更为复杂。通常我们会在以后实施它们。在添加更多技术之前,我们必须有一个坚如磐石的隐藏策略。
音频和视频是不同的,因此从现在起,我们将在使用的技术中对两者加以区分。
音频和丢包隐藏
对于音频而言,音频数据包的丢失几乎总是立即转化为一个或多个音频帧的丢失(我们通常每秒有 50 个音频帧)。
“跳过 “这些音频帧的效果并不好,因为当数据包丢失时,它将导致机械音频。
其他简单的方法包括回放接收到的最后一帧——按原样播放或降低音量。
更复杂的方法则是尝试通过机器学习(或者我们现在喜欢的叫生成式人工智能)来估计本应收到的内容。谷歌内部就有这样的能力(尽管不是在他们的 WebRTC 开源实现中)。如果你有兴趣了解更多相关信息,可以查看谷歌对 WaveNetEQ 的解释。
这里有几点需要记住:
- 在大多数情况下,这不是你能控制的,除非在设备端拥有/编译了 WebRTC 协议栈。
- 了解浏览器在此方面的行为方式后,你就可以更聪明地使用其他技术(决定何时使用以及使用的力度)。
- 在你自己的本地应用程序中?可以改进一些东西,但需要知道自己在做什么,而且你需要有令人信服的理由来走这条路。
视频和丢包隐藏
视频在丢包的情况下更为棘手:
- 在视频编码中,每个帧通常都依赖于过去的帧(以提高压缩率)
- 一个视频帧几乎总是由多个数据包组成
一个数据包的丢失就意味着一个帧的丢失,很容易造成整个视频序列的丢失:
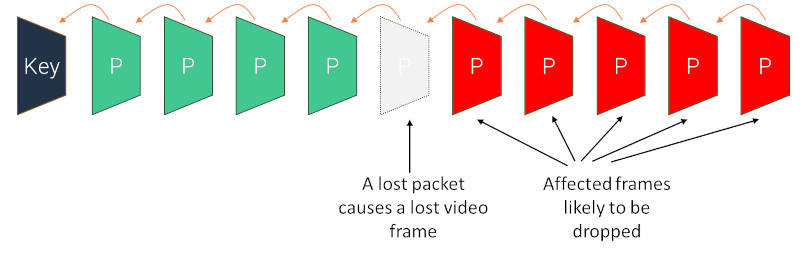
视频中的丢包隐藏意味着丢帧,通常会冻结视频,直到下一个关键帧到来。
接收方在发生这种丢包时能做什么?如果接收方认为无法迅速恢复(这是最常见的情况),他可以通过 RTCP 向发送方发送 FIR 或 PLI 消息。这些信息向发送方表明,有一个丢失需要处理,通常的解决办法是重置编码器并发送一个新的关键帧。
过去,系统会在不丢失数据包的情况下继续解码,以克服数据包丢失的问题。最终的结果是在新的关键帧到来之前,视频上出现模糊的伪影。如今,最佳做法是冻结视频,直到出现关键帧(所有浏览器实现都是这样做的)。
这里有几点需要记住:
- 与音频相比,在这里有更多的控制权。这是因为数据包丢失意味着你将在另一端收到 FIR 或 PLI 消息。如果你的媒体服务器接收到这些信息,你可以决定如何回应
- 发送关键帧意味着要为该帧投入更多比特率。如果网络拥塞,这只会增加负担。大多数媒体服务器会避免在大型群组会议中发送过多的关键帧
- 有一些视频编码技术可以减少帧与帧之间的依赖性。这些技术包括时域可扩展性(Temporal Scalability) 和 SVC
重传丢失的数据包 (RTX)
如果数据包丢失,我们可以采取的第一个解决办法就是重新传输。
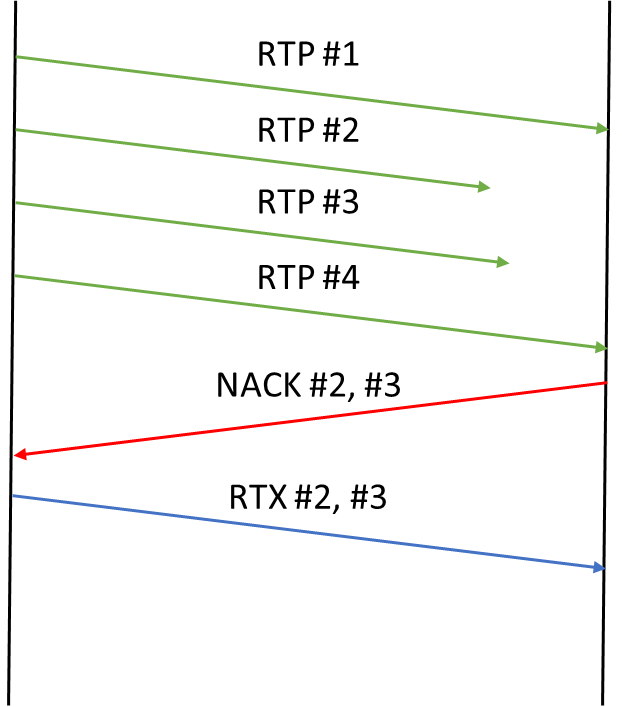
接收方知道丢失了哪些数据包。一旦发送方知道丢失的数据包(通过
NACK 报文),就可以将它们作为 RTX 数据包重新发送。
就网络资源而言,重传是最经济的解决方案。它是浪费最少的解决方案,但也是最难利用的解决方案。这是因为它最终看起来像这样:
为了重新传输,我们需要:
- 知道有数据包丢失(通过接收较新的数据包)
- 判定旧数据包不会到达并丢失
- 让发送方知道它们丢失了
- 让发送方重新传输
这需要时间,很长时间。
那么问题就来了,重发是否为时已晚。
视频和 RTX
视频可以真正利用重传(在 WebRTC 中也是如此)。
通过视频压缩,我们可以对帧进行分级。有些帧比其他帧更重要:
- 关键帧(或 I 帧)是最重要的。它们是 “独立 “的帧,不依赖于任何过去的帧。
- 在 SVC 和时序可扩展性中,有些帧是一种死胡同,不依赖于任何帧,而在其他情况下,则有帧依赖于它们
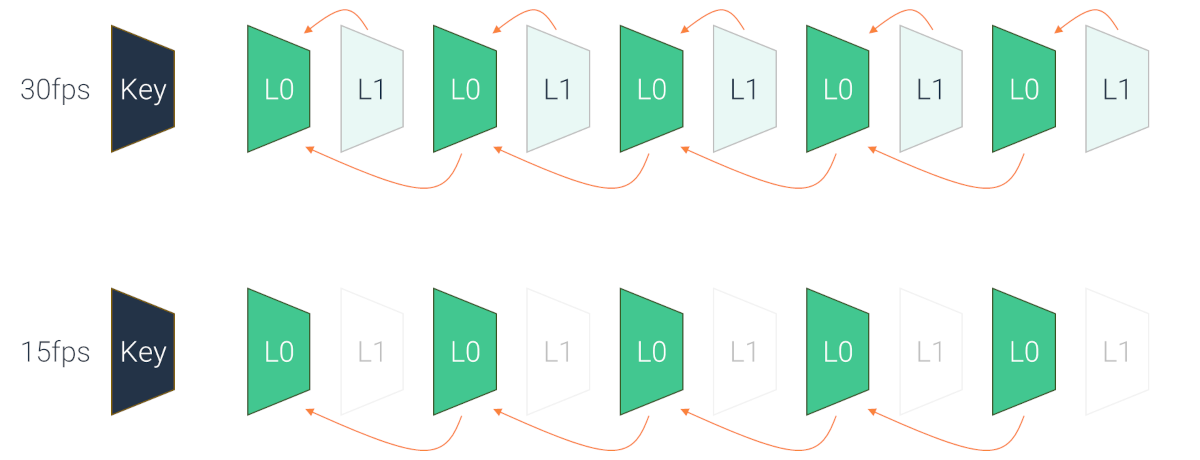
例如,上图展示了关键帧和时间扩展性如何构建依赖链。 L0 帧的可用性高于 L1 帧(L1 帧依赖于 L0 帧,而 L0 帧什么都不依赖)。
有了这样帧依赖树,我们就能利用弹性做一些有趣的事情。其中之一就是决定是否值得要求重传:
- 如果丢失的数据包来自一个关键帧,那么即使关键帧本身由于时间已过而无法显示,请求重传也是有用的。
- 同样,我们可以决定对 L0 帧也这样做(这些很重要)
- 我们还可以跳过丢失的 L1 帧数据包,一旦重传到达,我们可能来不及重放这一帧,而这些数据都是无用的。
音频和 RTX
音频压缩与视频压缩的依赖关系树不同。这就是为什么 libwebrtc 没有处理音频 RTX 的代码。
为音频提供 RTC 会有用吗?可以。出于唇语同步的目的,音频数据包通常会等待视频数据包到达。如果我们能利用等待时间进行重传,就能提高音频质量。谷歌可能认为这一点不够重要。
提前纠正数据包丢失(FEC)
我们可以要求事后重传,但如何确保没有必要呢?这就是 FEC(前向纠错)的意义所在。
这么想吧,如果我们只有一次机会发送我们想要发送的内容,而且这个内容超级重要。如果我们知道其中一份到达目的地的几率很高,那么发送 100 份这样的内容有意义吗?
FEC 就是发送更多可用来重建或替换丢失数据包的数据包。
可以使用不同的 FEC 方案,其中主要有三种:
- 重复(一遍又一遍地发送相同的内容)
- XOR(添加与我们希望保护的数据包进行 XOR 运算的数据包)
- Reed Solomon(与 XOR 类似,但更复杂且更具弹性)
WebRTC 开箱即支持复制和 XOR。
FEC 的最大障碍是它对比特率的使用——在这方面它对网络资源消耗很大。
音频前向纠错
音频 FEC 有两种不同的方式:
- 编解码器内 FEC(如 Opus 带内 FEC),FEC 机制是编解码器实现本身的一部分
- 基于 RTP 的 FEC,FEC 机制是 RTP 协议的一部分
带内 FEC 是作为 Opus 编解码器库的一部分实现的。它充其量只能算是还行,没有什么值得一提的。
然后是 RED(冗余编码),每个音频数据包都包含多个音频帧。而且所保存的音频帧都是稍旧的,这样如果一个数据包丢失,我们就能在另一个数据包中得到它。
RED 在 libwebrtc 中实现。对 RED 的支持仅限于 1 级冗余(即最多恢复一个连续丢失的数据包)。不过,你可以使用 WebRTC 的 Insertable Streams 机制在浏览器中以更高冗余度或动态冗余度生成 RED 数据包。
视频前向纠错
对于视频来说,FEC 是一种浪费。如果我们需要将比特率提高 20% 或更多才能使用 FEC 实现稳健性,那么这将以牺牲视频质量为代价,而我们可以通过提高视频比特率来提高视频质量。
在大多数情况下,WebRTC 会忽略视频的 FEC,这很可惜。使用时间可扩展性或 SVC 时,我们可以决定只重传重要的数据包,同样,我们也可以决定只对更重要的帧添加 FEC 保护。
总结
处理 WebRTC 中的丢包问题并不简单。随着时间的推移,它变得越来越复杂,因为在实现过程中会附加更多的技术和优化。以上所列的方法希望能够帮助到你。
彩蛋:
ZEGO即构实时音视频 SDK 在实时性的表现:50% 丢包或抖动 400ms 以内,ZEGO ⾳视频服务端到端时延不超过 600ms,提供⾼质量实时观看体验;70% 丢包或抖动 1000ms 极端弱⽹环境下,时延能控制在 1000ms 以内,保持流畅的通话体验。
如果你想更快在业务上实现高质量的音视频体验,现在可以免费注册体验。



